Kaggle Salt Identification Challenge or how to segment images
Top 1% (28/3229) solution write-up, based on a single 5-Unet like model with hflip TTA (test time augmentation) and few other tricks.*
Our team: Insaf Ashrapov, Mikhail Karchevskiy, Leonid Kozinkin The task was to accurately identify if a subsurface target is a salt or not on seismic images.
-
Originally posted on Medium.
-
Gitgub repo
Input Data
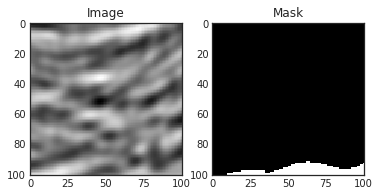 Salt image and its corresponding mask
Salt image and its corresponding mask
Initially, we had grayscale 1 channel input image with a size of 101*101. To make it usable with pretrained encoders we adjusted them to 128x128 with the 1st channel as the source image by padding, the 2nd channel we used relative depth:
Relative depth = (current depth — minimum depth )/(maximum depth — minimum depth)
On the third channel, we have applied CoordConv [1] . We tried higher resolution but faced much slower learning and convergence without getting any improvements, but some other participants reported notable improvement.
Augmentations
We used such augmentations from the great albumentation library: brightness, blurs, hflip, scale, rotate and contrast. The important things here was not to use image augmentations which are unnatural or physically impossible for the provided dataset, for example, vertical flip only negatively affected due. In addition, these augmentations weren’t too heavy, otherwise, we suffered lower segmentation quality and even speed of training.
Base model
Our final model was based on Unet [2] with some tricky modifications just like everyone else made.
SE-ResNeXt-50[3] (it outperformed all Resnets and more complex SE-ResNeXt-101) as the encoder for getting the initial feature map. However, we modified the first layer. Firstly we have been using it without max pooling, but then switched on using with stride = 1 by returning back max pooling. Both mentioned modification allowed to use 128*128 images, otherwise higher image resolution was required. From my perspective scaling images brings some unnecessary artifacts to the images and masks as well.
ScSE (Spatial-Channel Squeeze & Excitation) [4] both in Encoder and Decoder, Hypercolumn [5].
Surprisingly for us, we have removed all dropouts. That was substantial because speeded up the training and improved the final result. We even tried to use only 16 filters but ended up using 32. Seems to be augmentation and 5-fold averaging was enough to avoid overfitting.
Training
For learning purposes we used such parameters and approaches: Batch size 20 (maximum size that fitted into GPU memory), Adam [6], Cyclic learning rate [7] with parameters mode=’triangular2’, baselr=1e-4, maxlr=3e-4, step_size=1500, heavy snapshot ensembling [8] (averaging last 10 best models with exponentially decreasing weights). Using snapshot ensembling made useless blending models or for such lb score lower models didn’t give any boost.
For the first 80 epochs, we trained with BCE (binary cross entropy) loss and then other up to 420 epochs 0.1 BCE + 0.9 Lovasz as a loss function [9]. However almost everytime training was stopped by ealystopping. Using only Lovasz also worked pretty well, but BCE speeded up initial training. We used 1080ti and 1070ti with pytorch for training. Unfortunately, Keras wasn’t so convenient to try on new things, moreover, Pytorch pretrained library of encoders is richer.
What else
We didn’t try two big promising things which could help us:
1) Pseudo labeling. Then you use predicted test images with high confidence in the train [10]. The first place placed this method as the main one, which boosted his score.
2) Deep semi-supervised learning [12]. This approach aims to use both labeled and unlabeled images. Here we supposed to train multiple deep neural networks for the different views and exploits adversarial examples to encourage view difference, in order to prevent the networks from collapsing into each other. As a result, the co-trained networks provide different and complementary information about the data, which is necessary for the Co-Training framework to achieve good results.
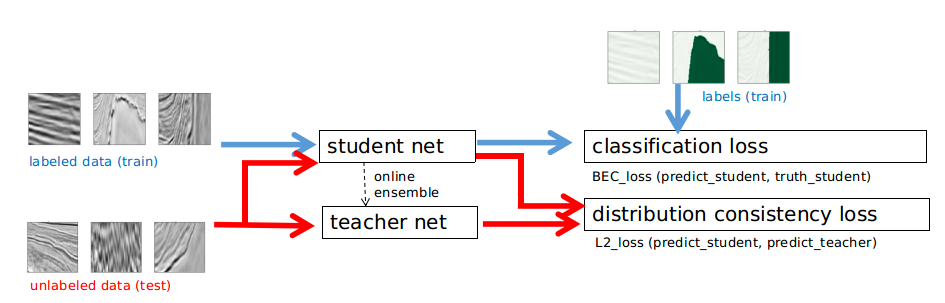 Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Image provided by Heng CherKeng
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Image provided by Heng CherKeng
Post Processing
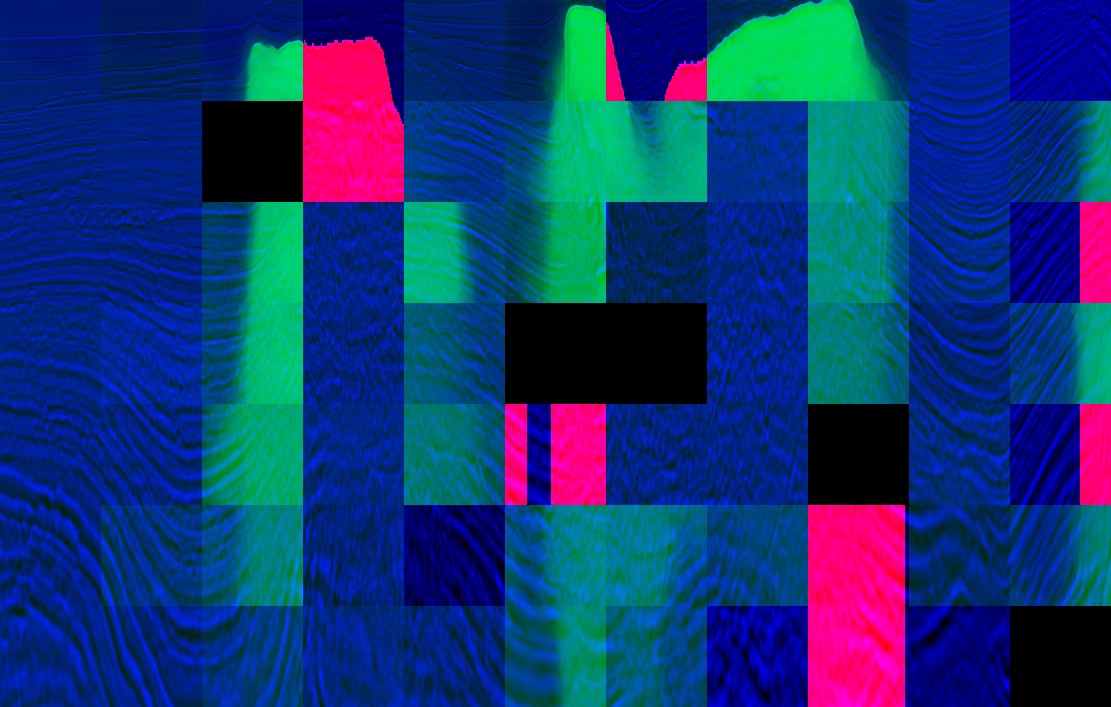 Puzzle created by Arthur Kuzin (red-train masks, green-predicted test masks)
Puzzle created by Arthur Kuzin (red-train masks, green-predicted test masks)
- Removing smalls masks and small independent masks (black and white) by using cv2.connectedComponentsWithStats (morphology didn’t work that well)
- Higher (0.40+) threshold gave us a better score on private LB, but for the public LB smaller threshold showed the same result.
- Jigsaw puzzles [10] didn’t give improvements on local validation so we didn’t use it on the final submission. Other participants reported high improvement only on the public leaderboard:
Publication
To broadcast our solution to a wider audience we have recently published the article to the arvix and posted our solution to Github.
References
- Liu, R., Lehman, J., Molino, P., Such, F.P., Frank, E., Sergeev, A., Yosinski, J.: An intriguing failing of convolutional neural networks and the coordconv solution. arXiv preprint arXiv:1807.03247 (2018)
- Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional Networks for Biomedical Image Segmentation. In: Medical Image Computing and Computer-Assisted Intervention. pp. 234–241 (2015).
- Hu, J., et al.: Squeeze-and-excitation networks. arXiv:1709.01507 (2017) Abhijit G. R., Nassir N., Wachinger C. Concurrent Spatial and Channel Squeeze & Excitation
- in Fully Convolutional Networks arXiv:1803.02579 (2018)
- B. Hariharan, P. Arbeĺaez, R. Girshick, and J. Malik. Hypercolumns for object segmentation and fine-grained localization. InCVPR, 2015.
- D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- Leslie N Smith. Cyclical learning rates for training neural networks. In Applications of Computer Vision (WACV), 2017 IEEE Winter Conference on, pp. 464–472. IEEE, 2017
- Gao Huang, Yixuan Li, Geoff Pleiss, Zhuang Liu, John E Hopcroft, and Kilian Q Weinberger. 2017. Snapshot ensembles: Train 1, get M for free. arXiv preprint arXiv:1704.00109 (2017).
- Berman, M., Rannen Triki, A., Blaschko, M.B.: The lovasz-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In: CVPR (2018)
- D. Kim, D. Cho, D. Yoo, and I. S. Kweon. Learning image representation by completing damaged jigsaw puzzles. In WACV, 2018.
- Lee, Dong-Hyun. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In ICML Workshop on Challenges in Representation Learning, 2013.12. A. Tarvainen, H. Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results arXiv:1703.01780 (2017)